Abstract
Long-horizon omnimodal question answering answers questions by reasoning over
text, images, audio, and video. Despite recent progress on OmniLLMs,
low-resource long audio-video QA still suffers from costly dense encoding,
weak fine-grained retrieval, limited proactive planning,
and no clear end-to-end optimization. To address these issues, we propose
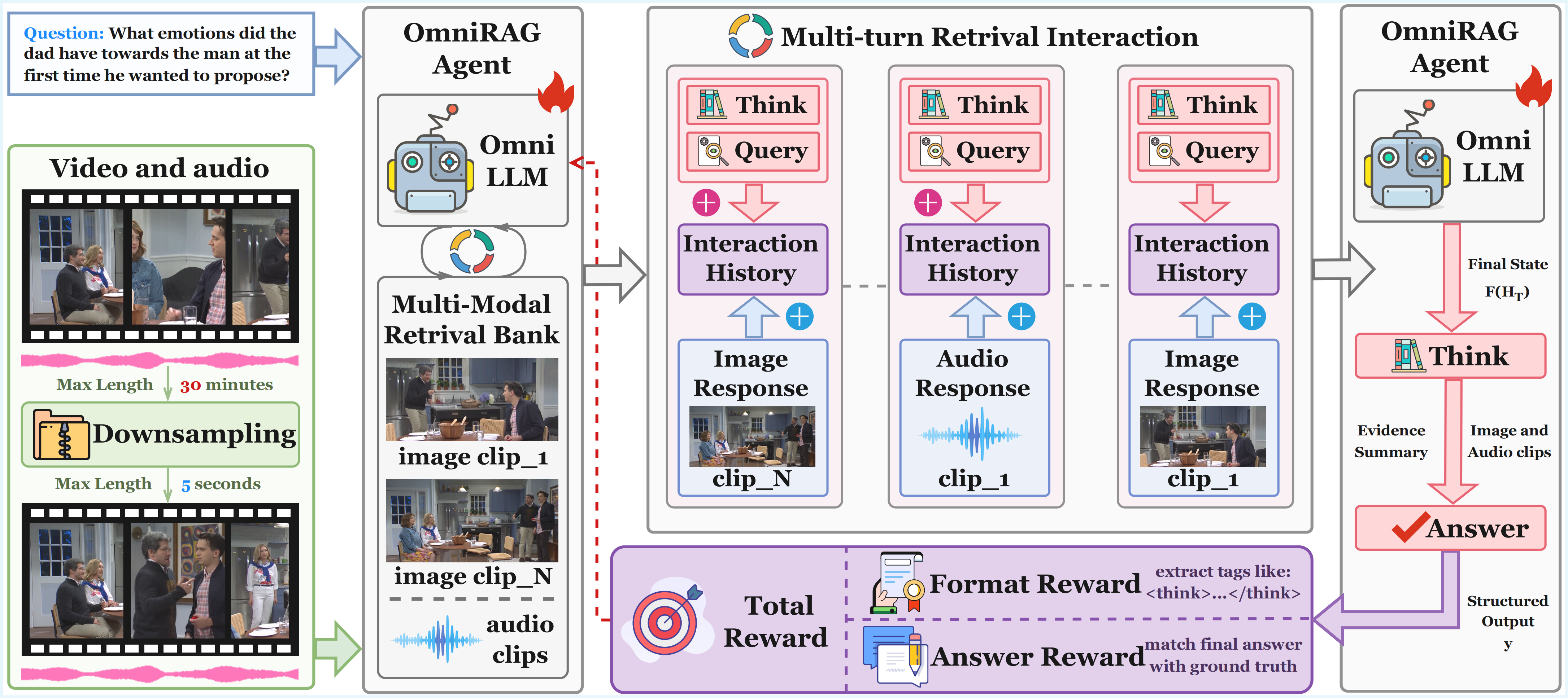
OmniRAG-Agent, an agentic omnimodal QA method for budgeted long
audio-video reasoning. It builds an image–audio retrieval-augmented generation
module that lets an OmniLLM fetch short, relevant frames and audio snippets from external banks.
Moreover, it uses an agent loop that plans, calls tools across turns, and merges
retrieved evidence to answer complex queries. Furthermore, we apply
group relative policy optimization (GRPO) to jointly improve tool use and answer
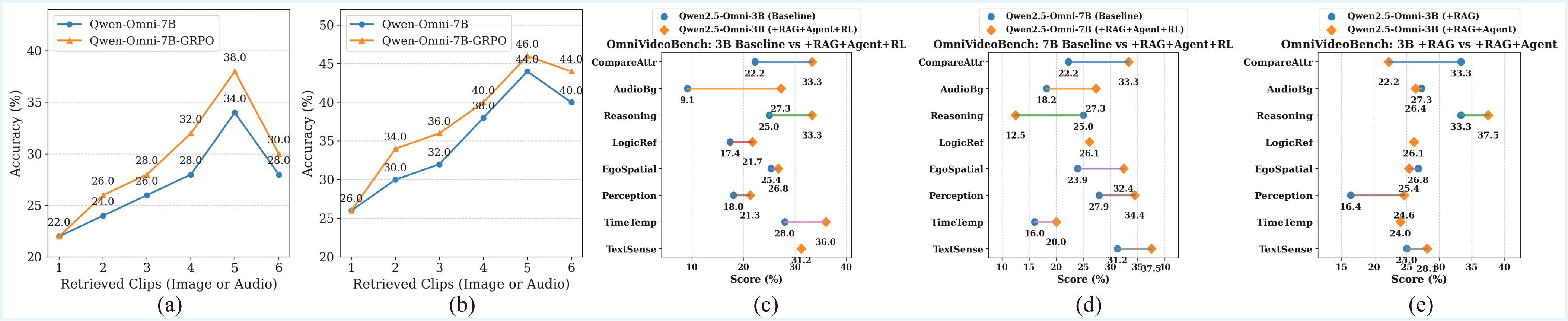
quality over time. Experiments on OmniVideoBench, WorldSense,
and Daily-Omni show that OmniRAG-Agent consistently outperforms prior methods
under low-resource settings and achieves strong results, with ablations validating each component.